
You are here: Start » Computer Vision » Deep Learning » DL_ReadCharacters_Multiple
DL_ReadCharacters_Multiple
| Header: | AVLDL.h |
|---|---|
| Namespace: | avl |
| Module: | DL_OCR |
Performs optical character recognition using a pretrained deep learning model on multiple regions of interest.
Syntax
void avl::DL_ReadCharacters_Multiple ( const avl::Image& inImage, const atl::Array<avl::Rectangle2D>& inMultiRoi, atl::Optional<const avl::CoordinateSystem2D&> inRoiAlignment, const avl::ReadCharactersModelId& inModelId, const atl::Array<int>& inCharHeights, const float inWidthScale, const float inCharSpacing, atl::Optional<const atl::String&> inCharRange, const float inMinScore, const float inMinQuality, avl::Polarity::Type inPolarization, const float inContrastThreshold, const bool inCalculateCandidates, const bool inRemoveBoundaryCharacters, atl::Optional<int> inCanvasWidth, atl::Optional<int> inCanvasHeight, const atl::Optional<avl::CharHints>& inCharHints, atl::Array <atl::Array<avl::OcrResult>> & outCharacters, atl::Array <atl::Array<atl::Array<avl::OcrCandidate>>> & outCandidates, atl::Array <atl::Array<avl::Region>> & outMasks, atl::Array<avl::Rectangle2D>& outAlignedRois, atl::Array<avl::Image>& diagCanvas )
Parameters
| Name | Type | Range | Default | Description | |
|---|---|---|---|---|---|
 |
inImage | const Image& | Input image | ||
|
inMultiRoi | const Array<Rectangle2D>& | Limits the areas where recognized characters are located | ||
|
inRoiAlignment | Optional<const CoordinateSystem2D&> | NIL | ||
|
inModelId | const ReadCharactersModelId& | () | Identifier of a Read Characters model | |
|
inCharHeights | const Array<int>& | {35} | Average height of characters in pixels for each ROI | |
|
inWidthScale | const float | 0.1 - 10.0 | 1.0f | Scales image width by the given factor |
|
inCharSpacing | const float | -0.5 - 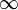 |
0.0f | Distance between characters denoted as fraction of inCharHeight |
|
inCharRange | Optional<const String&> | \"A-Z,a-z,0-9,\\\\\\\\,/,-\" | Limits the set of wanted characters | |
|
inMinScore | const float | 0.0 - 1.0 | 0.5f | Sets a minimum required score for a character to be returned |
|
inMinQuality | const float | 0.0 - 1.0 | 0.0f | Specifies the minimum quality threshold a character must meet to be returned. |
|
inPolarization | Polarity::Type | Any | Sets a required polarity for a character to be returned | |
|
inContrastThreshold | const float | -1.0 - 1.0 | 0.0f | Sets a threshold for a contrast of found characters |
|
inCalculateCandidates | const bool | True | If set to true then outCandidates is calculated | |
|
inRemoveBoundaryCharacters | const bool | False | If set to true characters that are not entirely contained in the ROI are filtered out | |
|
inCanvasWidth | Optional<int> | 64 - |
8192 | Maximum width of internal canvas buffer. If not set, dynamic size mode is used, used only on CUDA execution. |
|
inCanvasHeight | Optional<int> | 64 - 512 | 64 | Maximum height of internal canvas buffer. If not set, dynamic size mode is used, used only on CUDA execution. |
|
inCharHints | const Optional<CharHints>& | NIL | Specifies how ambiguous characters should be treated to improve recognition accuracy | |
 |
outCharacters | Array <Array<OcrResult>> & | |||
|
outCandidates | Array <Array<Array<OcrCandidate>>> & | Array of the most likely characters. The first element is the character from outCharacters | ||
|
outMasks | Array <Array<Region>> & | Masks of found characters (in Extended model). Contains empty regions in case of using model not supporting masks (in Fast and Balanced model). | ||
|
outAlignedRois | Array<Rectangle2D>& | Input rois after transformation | ||
 |
diagCanvas | Array<Image>& | Internal canvas images used for OCR |
Requirements
For input inImage only pixel formats are supported: 1⨯uint8, 3⨯uint8.
Read more about pixel formats in Image documentation.
Description
This tool locates and recognizes characters in multiple regions of interest in a single call. It is the multi-ROI counterpart to DL_ReadCharacters and is especially useful when several disjoint text fields have to be read on the same image (e.g. a label with separate fields, a date and a serial number, or several stamped areas on a single part). Without additional training, it is suitable for reading characters:
- horizontally oriented,
- of height between 60% and 140% of the corresponding inCharHeights entry (in pixels) - for the FastWide, Balanced, Extended or OcrA models,
- of height between 85% and 115% of the corresponding inCharHeights entry (in pixels) - for the Fast model,
- of height between 45% and 225% of the corresponding inCharHeights entry (in pixels) - for the Scalable model,
- being Latin letters (upper- or lower-case), digits or one of: !#$%&()*+,-./:;<=>?@[]^_`{|}~"'\€£¥
The pretrained models are described here.
Multi-ROI condition. The filter is designed for processing at least two ROIs in a single call - this is the path that actually exercises the multi-ROI (batched) execution and where the performance benefit over calling DL_ReadCharacters several times comes from. When inMultiRoi contains only a single rectangle, the filter internally falls back to the same code path as DL_ReadCharacters; in that case there is no advantage over calling DL_ReadCharacters directly, and using DL_ReadCharacters is recommended for clarity. The ROIs in inMultiRoi may differ in size, position and orientation; each ROI is processed with its own character height taken from the aligned inCharHeights array.
inMultiRoi and inRoiAlignment together limit the analysed area and may also be used to adjust to text which is not horizontally oriented. inMultiRoi and inCharHeights are array-synchronized - the i-th entry of inCharHeights provides the average capital-letter height (in pixels) for the i-th ROI. If a ROI contains characters of mixed heights, set the corresponding inCharHeights entry to the average of the capital-letter heights present in that ROI.
In case of fonts with exceptionally thin or wide symbols, inWidthScale may be used to reshape them to a more typical aspect ratio. The analysed area of every ROI will be scaled by inWidthScale in the horizontal axis. It may improve quality of results and help with tight inter-character spacing.
To limit the set of recognized characters, inCharRange may be used. This string has to be formatted according to the following rules:
- allowed characters have to be separated with commas,
- for ease of use, continuous range of letters or digits may be written as starting_character-ending_character, e.g. A-Z or 1-6,
- comma and backslash have to be prepended with backslash.
For example, inCharRange equal to A-F,g-o,0-9,X,Y,Z,-,\\,\, will result in recognizing only ABCDEFXYZghijklmno0123456789-\, characters.
The OcrResult.Score quantifies the aggregate confidence of the OCR pipeline. It is a composite metric derived from the probabilities of both the character localization (detection) and its subsequent identification (classification) stages. The inMinScore parameter may be used to change the minimum score of a returned character. By default, this threshold is set to 0.5. Lowering it may result in showing false characters.
The OcrResult.Quality is a score that assesses the physical quality of the character on the input image. This metric does not evaluate whether the OCR model read the character correctly, but rather whether the character is in good visual condition - clean, undamaged and legible. The inMinQuality parameter allows filtering out low-quality detections that might be noise or image artifacts rather than actual characters. By default it is 0.0 (nothing is filtered). Note: setting it too high may cause the model to ignore legitimate characters that are merely worn or poorly printed.
The inContrastThreshold and inPolarization parameters set a desired contrast interval of a character, which may be used to reduce the amount of false positives:
- For inPolarization = Polarity::Bright, only characters with a contrast greater than inContrastThreshold will be returned.
- For inPolarization = Polarity::Dark, only characters with a contrast lower than -inContrastThreshold will be returned.
- For inPolarization = Polarity::Any, only characters with a contrast lower than -inContrastThreshold or greater than inContrastThreshold will be returned.
A character which is darker than its background has a negative contrast; the opposite situation results in a positive contrast.
Using positive inCharSpacing can eliminate false detections of characters that are close to other characters. Conversely, using negative inCharSpacing can capture more characters that are located near each other. This value is set to 0 by default.
To filter out characters that are not fully contained within a given Region of Interest, use parameter inRemoveBoundaryCharacters. It is applied per-ROI.
Internal canvas - inCanvasWidth / inCanvasHeight
In the multi-ROI path each cropped ROI is first rescaled so that its character height becomes 35 pixels (the model's native height); the rescaled ROIs are then packed side-by-side with a 64-pixel separator into an internal canvas image that is fed to the network. If all rescaled ROIs fit into the canvas horizontally, a single inference call is performed; otherwise the ROIs are split across several canvas batches and one inference is run per batch. inCanvasWidth and inCanvasHeight control the size of this canvas buffer on CUDA:
- inCanvasWidth - default 8192, range <64, INF> with step 32.
- inCanvasHeight - default 64, range <64, 512> with step 32.
- The actual canvas used at runtime is
max(inCanvasWidth, widest rescaled ROI)×max(inCanvasHeight, tallest rescaled ROI). In other words these inputs act as a minimum; if a single ROI (after rescaling to char height 35) is wider than inCanvasWidth, the canvas grows to accommodate it. - If the set of ROIs does not fit into one canvas in the horizontal axis, the filter splits them into several canvas batches; each batch produces one inference call. Keeping inCanvasWidth comfortably larger than the typical total width of rescaled ROIs (plus 64-pixel separators) avoids extra batches.
- The editor defaults are 8192 for inCanvasWidth and 64 for inCanvasHeight, so by default both inputs are set and the NIL path below is not taken unless the user explicitly clears them.
- If both inputs are left unset (NIL), the dynamic-size mode is used - a single canvas is sized exactly to fit all rescaled ROIs. If only one of the two is NIL, the other is used together with an internal fallback for the unset one (4096 for width, 64 for height) as the minimum canvas size. Note that this internal width fallback differs from the editor default of 8192 - it only applies after the user deliberately clears the input.
- On CPU these inputs are ignored and a dynamic single-batch canvas is always used.
The diagnostic output diagCanvas contains the internal canvas images actually used for OCR - it is helpful when tuning the canvas dimensions.
Using DL_ReadCharacters_Deploy with DL_ReadCharacters_Multiple
DL_ReadCharacters_Deploy loads a Read Characters model in advance and returns an outModelId that should be fed into inModelId of this filter.
Does it actually speed up DL_ReadCharacters_Multiple? Yes, in two ways:
- The model is loaded (DLL open, graph build, weights transfer) during Initialize instead of during the first call to DL_ReadCharacters_Multiple. Model loading can take several seconds; without deploy this latency is paid on the first iteration.
- If inExecutionHint is set, an extra warm-up inference is executed on a dummy image of the hinted size (see
WarmupModelin the implementation). This primes back-end internal state for that input size - on CUDA it typically triggers kernel compilation / autotune. Without a matching warm-up, the first actual call pays this one-time cost. If the runtime input size differs from the hinted one, the warm-up may be partially redeemed and another preparation step can occur on the first mismatched call.
OcrDeployHint has three fields. They configure the warm-up only - they never override the runtime inputs of DL_ReadCharacters_Multiple:
- InputSize - size of the dummy image used for warm-up. For DL_ReadCharacters_Multiple on CUDA, the actual network input is the internal canvas described above; the most effective value here is therefore
Size(inCanvasWidth, inCanvasHeight)- by defaultSize(8192, 64). If you raise inCanvasWidth/inCanvasHeight at runtime, raise InputSize accordingly. - CharHeight - default 35. Keep this at 35. Internally, whenever the filter processes more than one ROI it forces its working character height to 35 (ROIs are rescaled to 35 before being placed on the canvas). Setting CharHeight to any other value in the hint would warm up the network with a mismatched internal resize scale and the benefit of warm-up would be partially lost on the first multi-ROI call. The value is independent from inCharHeights of DL_ReadCharacters_Multiple - per-ROI heights are still honored at runtime through the rescaling step.
- WidthScale - default 1.000. Match this to the inWidthScale you intend to pass to DL_ReadCharacters_Multiple at runtime. Conceptually it is independent from inWidthScale of DL_ReadCharacters_Multiple (the runtime value is what is applied to the canvas), but if the two differ a small extra resize-scale setup will happen on the first real call.
Recommended setup for DL_ReadCharacters_Multiple:
- Place DL_ReadCharacters_Deploy in the Initialize section and wire its outModelId to inModelId of DL_ReadCharacters_Multiple.
- Set inPretrainedModelType (or inModelDirectory), inDeviceType and inDeviceIndex to exactly the values the downstream filter will use.
- Fill inExecutionHint with:
InputSize = Size(inCanvasWidth, inCanvasHeight)- the same values you pass (or leave as default 8192×64) to DL_ReadCharacters_Multiple.CharHeight = 35(default).WidthScale =same as the runtime inWidthScale (default 1.0).
- On CPU, warm-up still loads the model in advance but the canvas size used at runtime is dynamic - setting a precise InputSize has limited value there.
- If different groups of ROIs require drastically different canvas sizes, add another DL_ReadCharacters_Deploy pre-configured for that second workload; the deploy call with the matching canvas size will be the one that primes kernels for those calls.
Canvas size and ROI / charHeight relationship
Before inference the filter rescales each ROI so that its characters become the model's native 35 pixels high. The rescaled ROIs are then packed side-by-side on the canvas with a 64-pixel separator between consecutive ROIs. For a set of N ROIs with widths roiW[i], heights roiH[i] and character heights charHeights[i]:
rescaledW[i] = roiW[i] * 35 / charHeights[i] rescaledH[i] = roiH[i] * 35 / charHeights[i] minCanvasWidth = sum( rescaledW[i] ) + (N - 1) * 64 // all ROIs in one batch minCanvasHeight = max( rescaledH[i] )
The canvas actually allocated at runtime is:
finalCanvasWidth = max( inCanvasWidth, max(rescaledW[i]) ) finalCanvasHeight = max( inCanvasHeight, max(rescaledH[i]) )
So inCanvasWidth / inCanvasHeight behave as a soft minimum: the canvas grows automatically to fit the widest / tallest rescaled ROI, but it is never smaller than the requested size. If the total width of the rescaled ROIs (plus separators) does not fit into finalCanvasWidth, the ROIs are split into several canvas batches and one inference is run per batch.
Boundary conditions (what triggers an error):
- inMultiRoi.Size() must equal inCharHeights.Size() - otherwise
DomainError. - Each ROI must have strictly positive dimensions and a total area ≥ 1 after alignment scaling - otherwise
DomainError("Nonpositive dimensions of ROI")/DomainError("Too small ROI"). - Each entry of inCharHeights must be ≥ 8 - otherwise
DomainError. - If inRoiAlignment is provided, its Scale must be > 0 - otherwise
DomainError("Zero scale in ROI alignment"). - inCanvasWidth and inCanvasHeight are not validated at runtime. Their ranges are enforced only by the editor metadata:
inCanvasWidth ∈ <64, INF>step 32 andinCanvasHeight ∈ <64, 512>step 32. Values outside those ranges passed programmatically are accepted by the filter, but very small values may lead to the canvas growing to fit a single ROI (see above) and very large values can still fail with anOutOfMemoryErrorfrom CUDA allocation.
Frequently asked questions
Can I pre-cache the canvas?
Yes. Place DL_ReadCharacters_Deploy in the Initialize section and fill inExecutionHint with InputSize = Size(inCanvasWidth, inCanvasHeight), CharHeight = 35 and WidthScale matching your runtime inWidthScale. This runs a warm-up inference on a dummy image of the requested canvas size, which triggers kernel compilation / autotune on CUDA so that the first real call to DL_ReadCharacters_Multiple no longer pays that one-time cost. Note that in the multi-ROI code path the filter always rescales every ROI to a 35-pixel character height before placing it on the canvas and drives the model's internal resize with a hard-coded charHeight = 35 - that is why CharHeight in the hint must stay at 35 regardless of the runtime inCharHeights.
How do I pick inCanvasWidth / inCanvasHeight for a known workload?
Compute the rescaled widths / heights for the worst-case set of ROIs (formula above), take the sum (with separators) as the target width and the max as the target height, round up to the next step of 32, and use those same values in both this filter and the matching inExecutionHint.InputSize of DL_ReadCharacters_Deploy. If your workload covers several distinct sizes, deploy once per size.
Hints
- It is recommended that the deep learning model is deployed with DL_ReadCharacters_Deploy first and connected through the inModelId input.
- If one decides not to use DL_ReadCharacters_Deploy, then the model will be loaded in the first iteration. It will take up to several seconds.
- To benefit from multi-ROI execution, provide at least two entries in inMultiRoi. With a single ROI this filter internally takes the same path as DL_ReadCharacters, so prefer DL_ReadCharacters in that case.
- inMultiRoi and inCharHeights are array-synchronized - sizes must match and each entry of inCharHeights must be at least 8.
- In case of characters with too much differing height within a single ROI, split that ROI into smaller ones containing symbols with a more consistent height.
- In case of poor quality results in Fast mode, check if every inCharHeights entry is set correctly (30–40 px is expected).
- False characters can also be removed using MergeCharactersIntoLines per ROI.
- To match a known inPattern, use grammar rules in MergeCharactersIntoLines.
- If the first call is noticeably slower than subsequent ones, fill inExecutionHint of DL_ReadCharacters_Deploy with InputSize = Size(inCanvasWidth, inCanvasHeight), CharHeight = 35 and WidthScale equal to your runtime inWidthScale.
- If the sum of widths of the rescaled ROIs (plus 64–pixel separators) exceeds inCanvasWidth, the filter will split them into several canvas batches and perform one inference per batch. Increasing inCanvasWidth (and matching it in inExecutionHint.InputSize of DL_ReadCharacters_Deploy) consolidates the calls into a single batch and reduces latency.
Remarks
This filter should not be executed along with a running Deep Learning Service as it may result in degraded performance or even out-of-memory errors.
inCanvasWidth and inCanvasHeight are effective only on CUDA execution; on CPU the canvas is sized dynamically.
Errors
List of possible exceptions:
| Error type | Description |
|---|---|
| DomainError | Empty image in DL_ReadCharacters_Multiple. |
| DomainError | inCharRange cannot be empty string. |
| DomainError | inModelDirectory cannot be empty string. |
| DomainError | Nonpositive dimensions of ROI in DL_ReadCharacters_Multiple |
| DomainError | The number of items in inCharHeights must be equal to the number of items in inRois in DL_ReadCharacters_Multiple. |
| DomainError | Too small ROI in DL_ReadCharacters_Multiple |
| DomainError | Values of inCharHeights in DL_ReadCharacters_Multiple must be at least equal to 8. |
| DomainError | Zero scale in ROI alignment in DL_ReadCharacters_Multiple |
| DomainError | Not supported inImage pixel format in DL_ReadCharacters_Multiple. Supported formats: 1xUInt8, 3xUInt8. |
See Also
- DL_ReadCharacters – Performs optical character recognition using a pretrained deep learning model.
- DL_ReadCharacters_Deploy – Loads a deep learning model and prepares its execution on a specific target device.
- DL_LocateText – Performs text detection using a pre-trained deep learning model.
- MergeCharactersIntoLines – Converts a output of Deep Learning filter DL_ReadCharacters to lines of text.