AvsFilter_DL_ClassifyObject_Deploy
| Header: |
AVL.h
|
| Namespace: |
avl |
| Module: |
DL_CO |
Loads a deep learning model and prepares its execution on a specific target device.
Syntax
void avl::AvsFilter_DL_ClassifyObject_Deploy
(
const avl::ClassifyObjectModelDirectory& inModelDirectory,
const atl::Optional<avl::DeviceKind::Type>& inDeviceType,
const int inDeviceIndex,
const bool inCreateHeatmapHint,
avl::ClassifyObjectModelId& outModelId
)
Parameters
|
Name |
Type |
Range |
Default |
Description |
 |
inModelDirectory |
const ClassifyObjectModelDirectory& |
|
|
A Classify Object model stored in a specific disk directory |
|
inDeviceType |
const Optional<DeviceKind::Type>& |
|
NIL |
A type of a device selected for deploying and executing the model. If not set, device depending on version (CPU/GPU) of installed Deep Learning add-on is selected. If not set, device depending on version (CPU/GPU) of installed Deep Learning add-on is selected. |
|
inDeviceIndex |
const int |
0 - 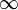 |
0 |
An index of a device selected for deploying and executing the model. |
|
inCreateHeatmapHint |
const bool |
|
False |
Prepares the model for a relevance heatmap creation in advance |
 |
outModelId |
ClassifyObjectModelId& |
|
|
Identifier of the deployed model |
Hints
- In most cases, this filter should be placed in the INITIALIZE section.
- Executing this filter may take several seconds.
- This filter should be connected to AvsFilter_DL_ClassifyObject through the ModelId ports.
- You can edit the model directly through the inModelDirectory. Another option is to use the Deep Learning Editor application and just copy the path to the created model.
- If any subsequent AvsFilter_DL_ClassifyObject filter using deployed model is set to create a relevance heatmap, it is advisable to set inCreateHeatmapHint to true.
In other case, inCreateHeatmapHint should be set to false. Following this guidelines should ensure an optimal memory usage and no performance hit on first call to AvsFilter_DL_ClassifyObject.
Remarks

- Passing NIL as inTargetDevice (which is default), is identical to passing DeviceKind::CUDA on GPU version of Deep Learning add-on and DeviceKind::CPU on CPU version on Deep Learning add-on.
- GPU version of Deep Learning add-on supports DeviceKind::CUDA and DeviceKind::CPU as inTargetDevice value.
- CPU version of Deep Learning add-on supports only DeviceKind::CPU as inTargetDevice value.
See Also
