
You are here: Start » User Interface » Creating Text Recognition Models
Creating Text Recognition Models
Text recognition editor creates an OCR model for getting text from regions. More details about the OCR technique can be found in Machine Vision Guide: Optical Character Recognition.
To create an OCR model a set of characters should be collected. If recognition score is low after training based on real samples then artificial character variations can created.
Creation of a model consists of following steps:
-
Collecting real samples - after opening the editor characters are visible and can be added to a training set.
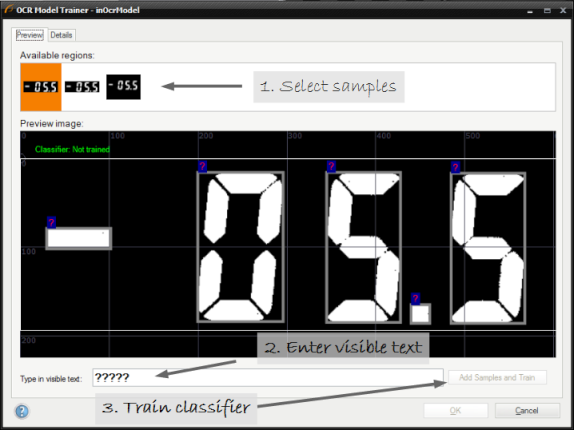
After the training character samples can be viewed in the details tab:
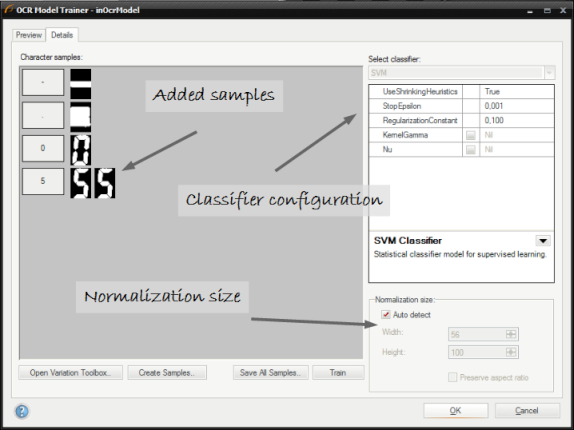
-
Creating artificial samples - when no samples are available user can create a training set using systems fonts.
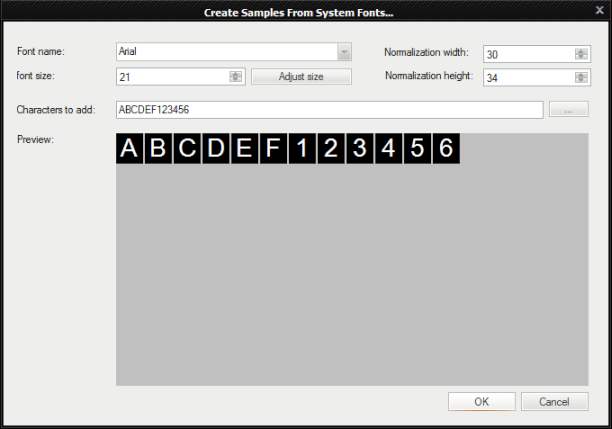
-
Creating character variations in case when no more samples are available and the training result is not fine the editor can modify existing samples to create a new set.
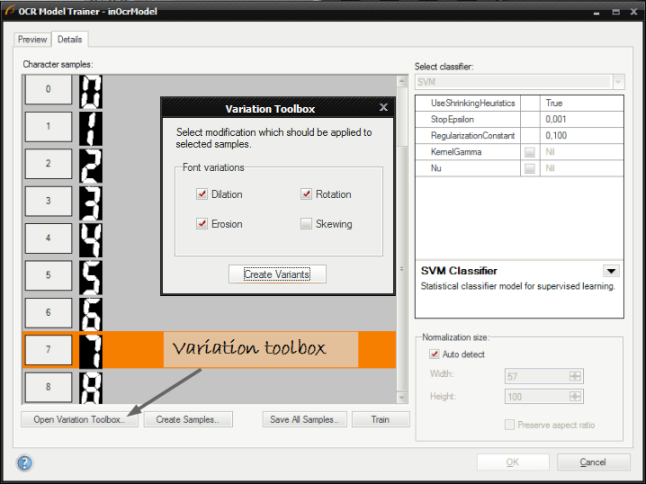
The training set after adding new samples variations:
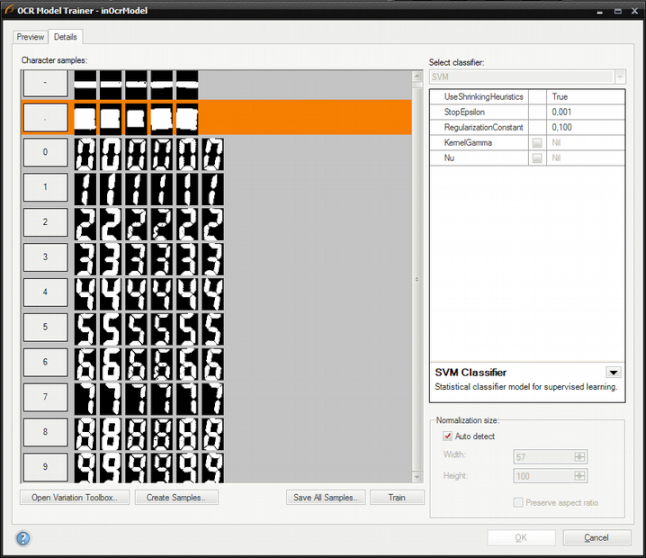
-
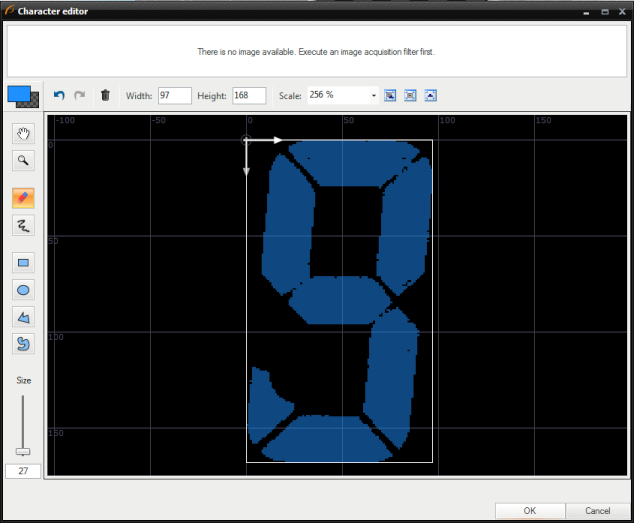
Editing samples - in case when gathered samples contain noises, or its quality is low, user can edit them manually. The image below show how to edit a character '8' to get character '9'.
Note:
- Each training character should have this same number of samples.
- In cases when some characters are very similar number of samples can be increased to improve classification.
- Character samples can be stored in an external directory to perform experiments on them.
| Previous: Creating Golden Template V2 Models | Next: Analysing Filter Performance |