
DeepLearning_SegmentInstances
| Header: | AVLDL.h |
|---|---|
| Namespace: | avl |
Performs instance segmentation using a trained deep-learning model.
Syntax
void avl::DeepLearning_SegmentInstances ( const avl::Image& inImage, atl::Optional<const avl::Region&> inRoi, const avl::DeepModel_InstanceSegmentation& inDeepModel, const atl::Optional<float>& inMinDetectionScore, const atl::Optional<int>& inMaxObjectsCount, atl::Array<avl::Box>& outBoundingBoxes, atl::Array<int>& outClassIds, atl::Array<atl::String>& outClassNames, atl::Array<float>& outScores, atl::Array<avl::Region>& outMasks )
Parameters
| Name | Type | Range | Default | Description | |
|---|---|---|---|---|---|
 |
inImage | const Image& | Input image | ||
|
inRoi | Optional<const Region&> | NIL | Area of interest | |
|
inDeepModel | const DeepModel_InstanceSegmentation& | Trained model | ||
|
inMinDetectionScore | const Optional<float>& | 0.0 - 1.0 | NIL | Minimal score of found objects |
|
inMaxObjectsCount | const Optional<int>& | 1 - 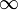 |
NIL | Maximal number of found objects |
 |
outBoundingBoxes | Array<Box>& | Bounding boxes of found objects | ||
|
outClassIds | Array<int>& | Ids of found objects classes | ||
|
outClassNames | Array<String>& | Names of found objects classes | ||
|
outScores | Array<float>& | Scores of found objects | ||
|
outMasks | Array<Region>& | Masks of found objects |
Requirements
For input inImage only pixel formats are supported: 1⨯uint8, 3⨯uint8.
Read more about pixel formats in Image documentation.
Hints
Loading Deep Learning Model may take longer timer. Consider using DeepLearning_LoadModel_InstanceSegmentation for pre-loading model before execution starts.
Remarks
- Model provided on inDeepModel input will be loaded to service automatically on first usage of Deep Learning filters.
- These filters only communicates with service and cannot be use for parallel computation.
Errors
List of possible exceptions:
| Error type | Description |
|---|---|
| DomainError | Not supported inImage pixel format in DeepLearning_SegmentInstances. |
See Also
Models for Deep Learning may be created using Adaptive Vision Deep Learning Editor or using Training Api.